

背景介绍
大家好。本公众号覆盖数据分析、可视化、大模型等多个方向实用技巧分享,欢迎大家关注,具体可查看下面文章:
如果对你有帮助,还请关注下面公众号点赞关注转发,你的支持就是我创作的最大动力~
今天给大家分享数据分析高达17种高级图表可视化,并附带详细的python案例,干货满满~本文涉及的python库版本信息如下:
# !pip install great_tables==0.5.0
# !pip install polars==0.20.18
# !pip install mpl_font==1.1.0
# !pip install pywaffle==1.1.0
# !pip install ptitprince==0.2.7
# !pip install matplotlib_venn
# !pip install upsetplot==0.9.0
# !pip install plottable==0.1.5
# !pip install pyjanitor==0.26.0
# !pip install pynimate==1.3.0
本文目录
-
背景介绍
-
华夫图绘制
-
瀑布图精美可视化
-
云雨图+显著性展示
-
分组统计柱状图使用seaborn库快速实现分组统计柱状图
-
热力图:利用biokit库绘制精美热力图
-
同类型不同阶段对比图:使用双系列重叠图表示
-
滑珠图: 绘制滑珠图展示不同产品2个阶段的对比
-
多集合可视化效果使用韦恩图进行(2~3)维展示
-
UpSet图精美可视化展示
-
绘制精美表格图例
-
绘制精美表格迷你图
-
决策树模型结构精美可视化展示
-
使用dtreeplot库精美展示树模型结构
-
使用dtreeviz库精美展示树模型结构
-
使用pybaobabat库精美展示树模型结构
-
绘制数据分析指标拆解树
-
对dtreeplot的绘图代码进行解析
-
照猫画虎仿照绘制指标拆解树
-
最终输出结果
-
绘制精美展示山脊图和多维直方图
-
展示多维山脊图
-
展示多维直方图
-
动态图表: 利用Pynimate轻松绘制绘制
-
matplotlib实战基础教程
-
参考文档
华夫图绘制
PyWaffle库(其官方github:https://github.com/gyli/PyWaffle)是基于matplotlib库进行二次开发。主要用于绘制华夫图(象形图),只需要一行代码即可快速绘制,其支持高达2k多种象形图标。下面是常用的案例介绍
import matplotlib.pyplot as plt
from pywaffle import Waffle
data = {"sun": 30, "showers": 16, "snowflake": 4}
fig = plt.figure(
FigureClass=Waffle,
rows=5,
values=data,
colors=["#FFA500", "#4384FF", "#C0C0C0"],
icons=["sun", "cloud-showers-heavy", "snowflake"],
font_size=20,
icon_style="solid",
icon_legend=True,
labels=[f"{k}:{v}({int(v / sum(data.values()) * 100)}%)" for k, v in data.items()],
legend={ "ncol": len(data),"loc": "lower left", "bbox_to_anchor": (-0.05, -0.2),
"frameon": False,"fontsize": 12,'labelspacing':0.2,}
)
效果展示
![图片[1]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/2113ed594a20240519200524.png)
瀑布图精美可视化
瀑布图(Waterfall Chart)是一种专门用于表现数据在一系列变化后累积效果的图表类型,它通过一连串的垂直条形来可视化数据随时间或其他顺序变量的变化过程,尤其强调从一个初始值到最终值之间每个阶段对总体数值的贡献或影响。下面是利用python绘制的瀑布图。
index = ['初始值','1月份','2月份','3月份','4月份','5月份']
b = [10,-30,-7.5,-25,95,-7]
pf= pd.DataFrame(data={'A' : b},index=index)
pf['B'] = [20,10,-40,30,20,-10]
import mpl_font.noto
fig,axes = plt.subplots(2,1, figsize=(8,6), dpi=144)
ax = axes[0]
ax = waterfall_chart(pf,col_name='A',
ax=ax, formatting='{:,.2f}',
rotation_value=0, net_label='最终值',
Title='瀑布图可视化展示', x_lab='月份', y_lab='产量'
)
ax = axes[1]
ax = waterfall_chart(pf,col_name='B',
ax=ax, formatting='{:,.2f}',
rotation_value=0, net_label='最终值',
Title='瀑布图可视化展示', x_lab='月份', y_lab='产量',
green_color='#4BC0E7', red_color='#A07AED', blue_color='#C04BE7',
)
plt.show()
可视化展示![图片[2]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/44121b81e820240519200525.png)
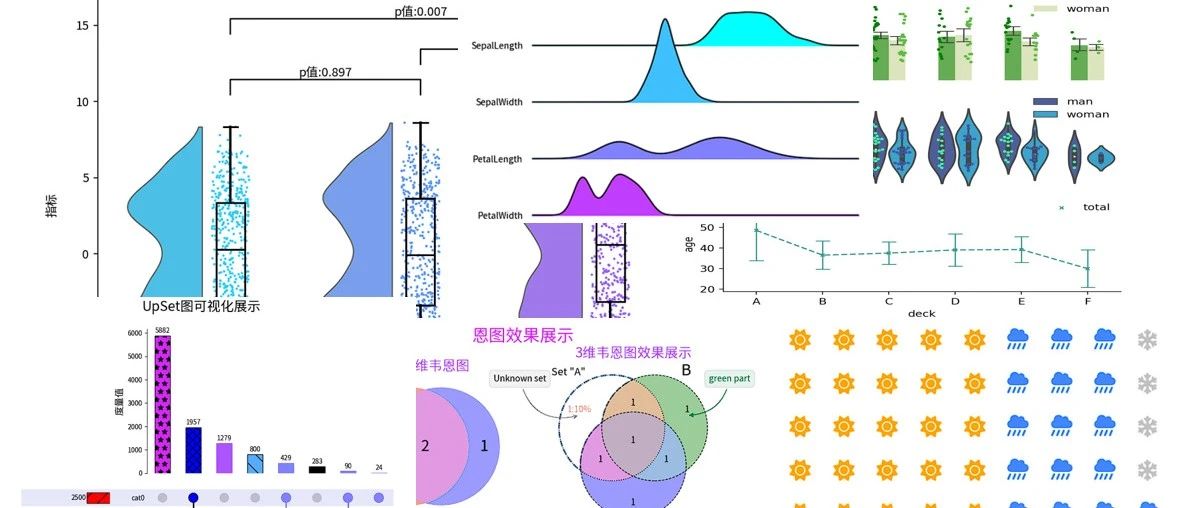
云雨图+显著性展示
云雨图(Raincloud plot)是一种结合了多种图形元素的统计图表,用于更全面地展示数据分布特征以及多个组别之间的比较。它通常包括以下几个组成部分:
-
云(Cloud):这部分采用核密度估计(Kernel Density Estimation, KDE)来描绘数据的概率密度分布,类似于小提琴图(Violin plot),但有时可能只显示一侧或者经过修改以减少视觉混乱。
-
伞(Umbrella):即箱线图(Boxplot)的部分,显示了数据的四分位数(最小值、下四分位数、中位数、上四分位数、最大值),概括了数据的基本集中趋势和离散程度。
-
雨(Rain):散布在箱线图下方的点状图,展示了每个数据点的位置,有助于观察单个数据值相对于整个分布的情况。
import mpl_font.noto
import matplotlib.pyplot as plt
from ptitprince import PtitPrince as pt
fig, ax = plt.subplots(figsize=(10, 6), dpi=144)
dy = "A"; dx = "Category"; ort = "v"
# 显示一半小提琴"云图"
ax=pt.half_violinplot(ax=ax, data = df, palette = "cool", bw=.2, linewidth=1,cut=0.,scale="area", width=.8, inner=None,orient=ort,x=dx,y=dy)
# 显示点状图"雨图"
ax=sns.stripplot(ax=ax,data= df, palette="cool", edgecolor="white",size=2,orient=ort,x=dx,y=dy,jitter=1,zorder=0)
# 显示箱型图
ax=sns.boxplot(data= df, color="black",orient=ort,width=.15,x=dx,y=dy,zorder=10, showcaps=True,boxprops={'facecolor':'none', "zorder":10},showfliers=True,whiskerprops={'linewidth':2, "zorder":10},saturation=1)
# 进行单边t检验&&绘制对应的效果
y= df['A'].max() + 0.8;h= 1;col = 'k'
pairs = [('type_A', 'type_B'), ('type_B', 'type_C'), ('type_A', 'type_C')]
for i, (group1, group2) in enumerate(pairs):
group1_values = df[df['Category'] == i]['A']
group2_values = df[df['Category'] == i+1]['A']
_, p_value = ttest_ind(group1_values, group2_values)
x1, x2 = groups.index(group1), groups.index(group2)
ax.plot([x1, x1, x2, x2], [y + (h*i), y + h + (h*i), y + h + (h*i), y + (h*i)], lw=1.2, c=col)
ax.text((x1+x2)*.5, y+h+(h*i), f'p值:{p_value:.3f}', ha='center', va='bottom', color=col)
y += h
# 配置坐标轴
ax.set_ylim(-11, y+h+3*h)
ax.set_xlim(left=-0.7, right=3.5)
ax.set_xticklabels(['type_A','type_B','type_C','type_D'],ha='right',rotation = 0,fontsize = 12) # 设置刻度标签
ax.set_title('云雨图+箱型图+显著性可视化展示',y=1.01)
ax.set_xlabel('不同类型')
ax.set_ylabel('指标')
ax.grid(False)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
fig.tight_layout()
plt.show()
可视化结果:![图片[3]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/4b148b41e220240519200527.png)
分组统计柱状图使用seaborn库快速实现分组统计柱状图
下面是利用seaborn库快速实现分组统计柱状图,对应的python案例如下。
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import warnings
print("matplotlib:", matplotlib.__version__)
warnings.filterwarnings("ignore")
titanic = sns.load_dataset("titanic")
df = titanic[titanic['who'].isin(['man','woman'])].query("deck!='G'")
print(df.describe())
from pandas.api.types import CategoricalDtype
df['deck']=df['deck'].astype( CategoricalDtype(categories=['A','B','C','D','E','F'], ordered=True))
df['deck'].unique()
f,axes = plt.subplots(3,1, figsize=(6,6.5),dpi=200, )
ax =axes[0]
ax=sns.barplot(data=df, x="deck",
y="age", hue="who", errorbar=("ci", 85),estimator=np.mean,
palette=['#5CBB45','#DEEBB5'],
capsize=.2,
width=0.5, #设置柱状图的宽度
errwidth=1,
ax=ax,orient='v',) #estimator=np.mean, ci=85,
sns.stripplot(data=df, x="deck",
y="age",hue="who",dodge=True,jitter=True, ax=ax,
palette=['green','#5CBB45'],size=3,orient='v',legend=False)
h, l = ax.get_legend_handles_labels()
ax.legend(h, ['man','woman'],ncol=1,frameon=False,loc='upper right')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.axes.xaxis.set_visible(False)
ax =axes[1]
sns.violinplot(data=df, x="deck",hue="who",palette=['#4057A8','#22AFE5'],
y="age",dodge=True, ax=ax,orient='v',legend=False)
ax=sns.swarmplot(data=df, x="deck",hue="who",size=3,palette=['#40F7A8','#4057A8'],
y="age",dodge=True, ax=ax,orient='v',legend=False)
h, l = ax.get_legend_handles_labels()
ax.legend(h, ['man','woman'],ncol=1,frameon=False,loc='upper right')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.axes.xaxis.set_visible(False)
ax.set_yticks([20*i for i in range(6)])
ax.set_yticklabels([20*i for i in range(6)])
ax =axes[2]
ax=sns.pointplot(data=df, x="deck", y="age", orient='v',dodge=True,
markers= "x",linestyles= "--",errwidth=1,
errorbar=("se",3 ), capsize=.2, scale=0.5, ax=ax,color='#43978F',join=True,label='total') #['#43978F','#ABD0F1']
h, l = ax.get_legend_handles_labels()
ax.legend(h, ['total'],ncol=1,frameon=False,loc='upper right')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.subplots_adjust(hspace=0.1)
plt.show()
可视化结果:
![图片[4]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/e4a7d959d720240519200529.png)
热力图:利用biokit库绘制精美热力图
当你需要展示二维数据的整体变化趋势时,你可以使用biokit库(https://github.com/biokit/biokit)来进行可视化展示,下面是一个案例分享;
# !pip install biokit==0.5.0
import pandas as pd
import numpy as np
from biokit.viz import corrplot
fig = plt.figure(figsize=(6,4),dpi=200)
fig.subplots_adjust(left=0.1, wspace=0.06, hspace=0.06)
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
df = pd.DataFrame(dict(( (k, np.random.random(10)+ord(k)-65) for k in ['A','B','C','D','E','F','G'])))
df = df.corr()
c = corrplot.Corrplot(df)
c.plot(fig=fig, ax=ax1, colorbar=True,method='circle', shrink=.9,lower='circle', label_color='red'
,cmap='cool')
c.plot(fig=fig, ax=ax2, colorbar=True, cmap='crest',method='square', shrink=.9 ,rotation=45)
c.plot(fig=fig, ax=ax3, colorbar=False, cmap='copper', method='text',)
c.plot(fig=fig, ax=ax4, colorbar=True, method='pie')
plt.show()
可视化结果:![图片[5]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/39220e64a420240519200531.png)
同类型不同阶段对比图:使用双系列重叠图表示
下面是一个案例展示利用双系列重叠图表示同类型不同阶段数据指标的变化情况。
from mplfonts.util.manage import use_font
use_font('Noto Sans CJK SC')
import matplotlib.pyplot as plt
import mplcyberpunk
import numpy as np
x = ['%d月'%i for i in range(1,13)]
y1 = np.array([45, 63, 49, 45,53,45,67,64,73,84,64,55])
y2 = np.array([25, 93, 29, 85,63,25,47,84,43,94,34,25])
# DCE9F4', '#E56F5E', '#F19685','#FFB77F', '#F6C957', '#FBE8D5']
with plt.style.context("cyberpunk"):
use_font('Noto Sans CJK SC')
fig, axes =plt.subplots(2,1,figsize=(6,2.5),dpi=200)
ax =axes[0]
ax.set_title("产品A实际完成和预计完成情况", fontsize=8)
delta_list = np.array([round((y2[i]-y1[i])/y1[i],4) for i in range(len(y1))])
colors = np.array(['#E56F5E' for _ in range(len(x))])
colors[delta_list<0]='#F6C957'
delta= ax.bar(x,delta_list,color=colors,width=0.4,)
for index,value in enumerate(y1):
if delta_list[index]>0:
ax.text(index,delta_list[index]+0.01, f'{delta_list[index]*100:0.2f}%', ha='center', va='bottom', color='#FBE8D5',fontsize=6,)
else:
ax.text(index,delta_list[index]-0.03, f'{delta_list[index]*100:0.2f}%', ha='center', va='top', color='#FBE8D5',fontsize=6,)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
ax.axhline(y=0, linestyle='--', color=(194/255,127/255, 159/255), linewidth=1)
ax.legend([delta],['完成率'],fontsize=6,ncol=2,loc='upper left')#'upper right',)
ax =axes[1]
o1= ax.bar(x,y1,color='#ABD0F1',width=0.6,label='实际值')
for index,value in enumerate(y1):
ax.text(index,value+8, f'{value}', ha='center', va='top', color='#E56F5E',fontsize=6,)
o2= ax.bar(x,y2,color='#43978F',label='预估值')
for index,value in enumerate(y2):
ax.text(index,value+8, f'{value}', ha='center', va='top', color='#E56F5E',fontsize=6,)
ax.set_yticks([10*i for i in range(15)])
ax.set_yticklabels([10*i for i in range(15)])
ax.grid()
mplcyberpunk.add_bar_gradient(bars=o1,ax =ax )
mplcyberpunk.add_bar_gradient(bars=o2,ax =ax )
ax.axes.yaxis.set_visible(False)
axes[0].legend([o1,o2,delta,],['实际值','预估值','完成率'],fontsize=6,ncol=3,loc='upper right')#'upper right',)
plt.subplots_adjust(hspace=0.01,wspace=0.01)
plt.show()
输出效果图:![图片[6]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/286604514920240519200533.png)
滑珠图: 绘制滑珠图展示不同产品2个阶段的对比
import pandas as pd
import seaborn as sns
import numpy as np
import mpl_font.noto
import matplotlib.pyplot as plt
import warnings
np.random.seed(2024)
df = pd.DataFrame({'2019':[42,21,53,16,23,10,20,65,16,34,13,25,18,25,14,26]})
df['Product'] = ['A_%d'%i for i in range(16)]
df['2020'] = df['2019'].apply(lambda x:x +30+ int(10*np.random.random()) )
df.loc[7,'2020']= 30
fig,ax = plt.subplots(figsize=(6,6),dpi=120,facecolor='white',edgecolor='white')
ax.set_facecolor('white')
#绘制线
ax.hlines(y=df.index+.03, xmin=df['2019'], xmax=df['2020'], color="k", lw=1)
#添加线标记
for i,v1,v2 in zip(df.index,df['2019'],df['2020']):
if v2>v1:
ax.text((v1+v2)/2,i+0.05,s="+%d"%(v2-v1),size=10,color='#ED1A1F',ha='left',va='bottom',fontweight='bold')
else:
ax.text((v1+v2)/2,i+0.05,s=v2-v1,size=10,color='#5CBB45',ha='left',va='bottom',fontweight='bold')
#绘制type_A散点
for i,j,text in zip(df.index,df['2019'],df['2019']):
ax.scatter(j,i,s=30,color='k')
#绘制type_B散点
for i,j,text in zip(df.index,df['2020'],df['2020']):
ax.scatter(j,i+.03,s=30,color='blue')
ax.set_xlim(left=-10,right=140)
#绘制竖线
ax.plot([0,0],[0,15],color='k',lw=1)
#绘制竖线上散点
for i in df.index:
ax.scatter(0,i,color='#172A3A',ec='k',s=2,zorder=3)
for index,i in enumerate(zip(df.index,df['2020'],df['Product'])):
if i[1] > 0 :
ax.text(0-1,index,i[2],color='#3D71A0',size=8,ha='right',va='center')
else:
ax.text(i[1]-1,index,i[2],color='#3D71A0',size=8,ha='right',va='center')
ax.axis('off')
#添加图例
ax.scatter([],[],marker='o', label='2019',color="k")
ax.scatter([],[],marker='o', label='2020',color="blue")
ax.legend(loc='best',frameon=False,markerscale=1.2,ncol=1,prop={'size':8,},columnspacing=.5)
ax.invert_yaxis()
ax.set_title("不同产品在2019年~2020年销售额变化情况(滑珠图)")
可视化结果:![图片[7]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/e53ace7a1c20240519200535.png)
多集合可视化效果使用韦恩图进行(2~3)维展示
matplotlib_venn库(其官方github:https://github.com/konstantint/matplotlib-venn)是基于 matplotlib 开发的一个专门用来绘制维恩图(Venn Diagrams)的第三方扩展库主要绘制二维和三维韦恩图。下面是案例介绍。
from matplotlib import pyplot as plt
import numpy as np
import mpl_font.noto
from matplotlib_venn import venn3, venn3_circles,venn2
fig,axes = plt.subplots(1,2, figsize=(8,4))
ax = axes[0]
sv= venn2(ax=ax,subsets = [{1,2,3},{1,2,4}], set_labels = ('Set1', 'Set2'),set_colors=('r','b'))
# 调整标签字体大小
for text in sv.set_labels:
text.set_fontsize(18) # 设置集合名称的字体大小
for text in sv.subset_labels:
text.set_fontsize(18) # 设置交并集区域标签的字体大小
ax.set_title("简单2维韦恩图",fontsize=16, color='#AA55FF')
ax = axes[1]
v = venn3(ax=ax,subsets=(1, 1, 1, 1, 1, 1, 1), set_labels = ('A', 'B', 'C'))
v.get_patch_by_id('100').set_alpha(1.0) #设置透明度
v.get_patch_by_id('100').set_color('white') #设置区域颜色
v.get_label_by_id('100').set_text('1:10%') #设置区域显示文本
v.get_label_by_id('100').set_color('#EA8379') #设置区域内的颜色
v.get_label_by_id('A').set_text('Set "A"') #设置区域内标签内容
v.get_label_by_id('B').set_fontsize(18) #设置B区域内标签的大小
v.get_patch_by_id('A').set_linestyle('dashed') #设置线圈格式
v.get_patch_by_id('A').set_linewidth(2) #设置线圈格式
v.get_patch_by_id('A').set_edgecolor('#547DB1') #设置外圈
c = venn3_circles(ax=ax,subsets=(1, 1, 1, 1, 1, 1, 1),
linestyle='--', # 'dashed'
linewidth=0.8,
color="black" # 外框线型、线宽、颜色
)
c[0].set_lw(1.0)
c[0].set_ls('dotted')
ax.annotate('Unknown set', xy=v.get_label_by_id('100').get_position() - np.array([0, 0.05]), xytext=(-70,40),
ha='center', textcoords='offset points', bbox=dict(boxstyle='round,pad=0.5', fc='gray', alpha=0.1),
arrowprops=dict(arrowstyle='->', connectionstyle='arc3,rad=0.5',color='gray'))
ax.annotate('great job',color='#547DB1',
xy=v.get_label_by_id('001').get_position() - np.array([0, 0.05]),
xytext=(-50,-30),
ha='center',
textcoords='offset points',
bbox=dict(boxstyle='round,pad=0.5', fc='#547DB1', alpha=0.1),
arrowprops=dict(arrowstyle='->', connectionstyle='arc3,rad=0.5',color='#547DB1'))
ax.annotate('green part',color='#098154',
xy=v.get_label_by_id('010').get_position() - np.array([0, 0.05]),
xytext=(50,40),
ha='center',
textcoords='offset points',
bbox=dict(boxstyle='round,pad=0.5', fc='#098154', alpha=0.1),
arrowprops=dict(arrowstyle='-|>', connectionstyle='arc3,rad=-0.4',color='#098154'))
ax.set_title("3维韦恩图效果展示",fontsize=16, color='#AA55FF')
fig.suptitle("恩图效果展示",fontsize=20,color='#D52AFF')
plt.show()
可视化效果:
![图片[8]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/2d9744ec3220240519200537.png)
UpSet图精美可视化展示
UpSet图(UpSet Plot)是一种现代化的多集合并集可视化工具,它有效地解决了传统二维韦恩图(Venn diagram)在展示高维度集合关系时的局限性,尤其是在处理大量集合及其交集时的优势更为明显。可以看出韦恩图在高维数据的扩展。
from upsetplot import UpSet
fig= plt.figure(figsize=(10,6),dpi=100)
upset = UpSet(ds,sort_by='cardinality',
intersection_plot_elements=6,
totals_plot_elements=3,
element_size=None,
show_counts=True,
facecolor= 'black'
)
# 设置左边的总量对应类别地样式
upset.style_categories(categories="cat0", shading_facecolor="lavender",
bar_edgecolor='black',
bar_facecolor ='red',
bar_hatch="/",
shading_linewidth=1)
upset.style_categories(
categories=["cat2","cat1"],
bar_facecolor="aqua", bar_hatch="xx", bar_edgecolor="black"
)
#设置最上面和中间散点图的柱状图样式: 只要满足cat1
upset.style_subsets(present="cat1", facecolor="#AA55FF", linewidth= 0.9)
#只要满足cat0
upset.style_subsets(present="cat0", facecolor="#807FFF", linewidth= 0.9)
#设置cat1和cat2设置为蓝色
upset.style_subsets(present=["cat1", "cat2"], facecolor="blue", hatch="xx", edgecolor='black')
#>=3000以上的设置为浅蓝色
upset.style_subsets(min_subset_size=3000, facecolor="#D52AFF", hatch="*",edgecolor='black',label='>3k')
#设置最上面和中间散点图的柱状图样式: 按照degree来设置
upset.style_subsets(max_degree=0, facecolor="#55AAFF" ,hatch="",edgecolor='black',label='度为0')
# upset.style_subsets(min_degree=2, facecolor="purple")
axes=upset.plot(fig=fig)
# 将最右边的图中关闭网格
axes['totals'].grid(False)
axes['intersections'].grid(False)
# 设置最上面柱状图的y轴标签
axes['intersections'].set_ylabel("度量值", fontsize=14)
# 关闭最上面柱状图的图例
axes['intersections'].legend(frameon=False)
# 设置最右边柱状图的x轴标签
axes['totals'].set_xlabel("总量", fontsize=14)
plt.suptitle("UpSet图可视化展示",fontsize=20)
plt.show()
输出的结果:![图片[9]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/24a921d8a520240519200538.png)
绘制精美表格图例
plottable库(其官方github:https://github.com/znstrider/plottable)是专门可视化表格展示的神器,其底层是基于matplotlib开发的,展示效果惊艳,修改代码少,非常好用。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib.colors import LinearSegmentedColormap
import mpl_font.noto
from plottable import ColumnDefinition, Table
from plottable.formatters import decimal_to_percent
from plottable.plots import bar, percentile_bars, percentile_stars, progress_donut
# cmap = LinearSegmentedColormap.from_list(
# name="bugw", colors=["#ffffff", "#f2fbd2", "#c9ecb4", "#93d3ab", "#35b0ab"], N=256
# )
np.random.seed(2024)
pf = pd.DataFrame(np.random.random((5, 4)), columns=["A", "B", "C", "D"]).round(2)
pf.index.set_names("序号",inplace=True)
fig, axes = plt.subplots(1,2,figsize=(10,5),dpi=100)
Table(pf,ax=axes[0]
,odd_row_color="#f0f0f0"
, even_row_color="#e0f6ff"
)
axes[0].set_title("原始数据如下")
Table(pf
,ax=axes[1],
cell_kw={
"linewidth": 0,
"edgecolor": "k",
},
textprops={"ha": "center"},
column_definitions=[
ColumnDefinition("index", textprops={"ha": "left"}),
ColumnDefinition("A", plot_fn=percentile_bars, plot_kw={"is_pct": True}),
ColumnDefinition(
"B", width=1.5, plot_fn=percentile_stars, plot_kw={"is_pct": True}
),
ColumnDefinition(
"C",
plot_fn=progress_donut,
plot_kw={
"is_pct": True,
"formatter": "{:.0%}"
},
),
ColumnDefinition(
"D",
width=1.25,
plot_fn=bar,
plot_kw={
"cmap": plt.cm.cool,
"plot_bg_bar": True,
"annotate": True,
"height": 0.5,
"lw": 0.5,
"formatter": decimal_to_percent,
},
),
],
)
axes[1].set_title("经过精美化后数据展示")
plt.show()
输出结果:![图片[10]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/8a5c20073420240519200540.png)
绘制精美表格迷你图
基于Great_tables库(https://posit-dev.github.io/great-tables/get-started/basic-header.html),任何人都可以在Python中轻松创建出外观精美的表格,下面是一个python案例展示。
out=(
GT(pl.from_pandas(pf))
.tab_header(
title = md("使用great_tables来绘制迷你图样式汇总"),
subtitle = "包含折线图、柱状图、横向柱状图、点棒图"
)
.opt_align_table_header(align="center")
.fmt_nanoplot(columns="string_number"
, plot_type="bar"
,reference_line="max"
,reference_area=["q1", "q3"]
,options=nanoplot_options(
data_point_radius=8,
data_point_stroke_color="black",
data_point_stroke_width=2,
data_point_fill_color="white",
data_line_type="straight",
data_line_stroke_color="brown",
data_line_stroke_width=2,
data_area_fill_color="orange",
vertical_guide_stroke_color="green",
),
)
#reference_line in ("mean", "median", "min", "max", "q1", "q3", "first", or "last")
.fmt_nanoplot(columns="numbers",
reference_line="max",
reference_area=["q1", "q3"],
autoscale=True)
.fmt_nanoplot(columns="hbar_number", plot_type="bar")
.fmt_nanoplot(columns="lines")
.fmt_nanoplot(
columns="temperatures",
plot_type="line",
expand_x=[5, 16],
expand_y=[10, 40],
options=nanoplot_options(
show_data_area=False,
show_data_line=False
)
)
.cols_label(
example=html("索引"),
string_number=html("面积柱状图"),
numbers=html("面积折线图"),
temperatures=html("点状图"),
hbar_number=html("横向柱状图"),
lines=html("点棒图"),
)
.cols_align(align="center", columns="lines")
.tab_source_note(
source_note="Source:本图由Z先生的备忘录制作"
)
.tab_source_note(
source_note=md("Reference: https://posit-dev.github.io/great-tables/get-started/")
)
)
out
可视化展示:![图片[11]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/4b2614960220240519200541.png)
决策树模型结构精美可视化展示
使用dtreeplot库精美展示树模型结构
dtreeplot库(其github:https://github.com/suyin1203/dtreeplot)是一款简易的决策树可视化库,只需要使用少量的代码就可以展示树模型结构,下面是一个简单的python案例精美展示决策树模型。
import sklearn
print("sklearn: ", sklearn.__version__) # sklearn: 1.2.2
from dtreeplot import model_plot
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
X, y = datasets.make_classification(n_samples=30000,
n_features=10,
weights=[0.96, 0.04],
random_state=5)
features = [f'Var{i+1}' for i in range(X.shape[1])]
clf = DecisionTreeClassifier(criterion='gini',
max_depth=3,
min_samples_split=30,
min_samples_leaf=10,
random_state=2024)
model = clf.fit(X, y)
model_plot(model, features, labels=y, height=530)
树模型可视化结果:![图片[12]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/4dd509002520240519200543.png)
显示中文字体:
#第一步:先将对应的js文件拷贝到当前目录
# !git clone https://github.com/suyin1203/dtreeplot
# !mv dtreeplot/dtreeplot/* ./
# !rm -rf dtreeplot
#第二步:修改model_plot函数中的_plot_tree函数
html_content = string.Template("""
<meta charset="UTF-8">
...
""")
#第三步:设置显示的特征名称为中文,并执行结果
features = [f'特征{i+1}' for i in range(X.shape[1])]
树模型可视化结果(显示中文字体):![图片[13]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/d47c7a2aa820240519200545.png)
使用dtreeviz库精美展示树模型结构
dtreeviz(其github:https://github.com/parrt/dtreeviz)是一款精美的树模型可视化库,是基于matplotlib库的二次开发的,其通过一行代码就快速展示树模型的结果。下面是一个简单的python案例展示决策树模型结果。
!pip install dtreeviz==1.3.2
import dtreeviz
print("dtreeviz:", dtreeviz.__version__) # dtreeviz : 1.3.2
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from dtreeviz.trees import dtreeviz
from PIL import Image
import numpy as np
iris = load_iris()
clf = DecisionTreeClassifier(max_depth=5) # limit depth of tree
iris = load_iris()
clf.fit(iris.data, iris.target)
from mplfonts.util.manage import use_font
fontname='Noto Sans CJK SC'
use_font(fontname)
viz = dtreeviz(clf,
iris['data'],
iris['target'],
target_name='',
feature_names=np.array(iris['feature_names']),
class_names={0: '类别1', 1: '类别2', 2: '类别3'}, scale=1.5,
orientation='LR'
,fontname= fontname
) # ('TD', 'LR')
viz
输出结果:![图片[14]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/f99baef54520240519200546.png)
使用pybaobabat库精美展示树模型结构
pybaobabat(其github: https://github.com/dmikushin/pybaobab)是模拟树结构过程的一款可视化库,是基于matplotlib库进行二次扩展的,其可以快速展示树模型的结果。下面是一个简单的python案例展示决策树模型结果。
#!pip install pybaobabdt==1.0.1 pygraphviz==1.12
import pybaobabdt
from matplotlib.colors import ListedColormap
ax = pybaobabdt.drawTree(clf,
size=10,
dpi=100,
maxdepth=6, #设置渲染的树的最大深度
colormap=ListedColormap(["#01a2d9", "gray", "#d5695d","gray"]),
features=np.array(iris['feature_names']))
输出结果:![图片[15]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/034d9b1ca220240519200548.png)
绘制数据分析指标拆解树
在数据分析中,经常会对某个指标进行各个维度的拆解,这是通过指标拆解树可以清楚看到某度量指标在不同维度下的占比情况和整体的分布情况。
对dtreeplot的绘图代码进行解析
通过对绘图源码进行拆解发现其主要分为2部分;
-
第一部分:先通过_tree_to_json函数获得数据(待显示节点的明细和各个节点之间的关系)
plotter_js_path ='./js/plotter.js'
with open(plotter_js_path, 'r', encoding='utf-8') as f:
plotter_js_content = f.read()
container_id = "tree_plot_contid_" + uuid.uuid4().hex
# Converts the tree into its json representation.
features = [f'特征{i+1}' for i in range(X.shape[1])]
json_tree = _tree_to_json(model, features, y)
json_tree
对应的
{
'value': {'type': 'PROBABILITY','distribution': [0.9552, 0.0448], 'num_examples': '30000,4.48%'},
'condition': {'type': 'NUMERICAL_IS_HIGHER_THAN', 'attribute': '特征6', 'threshold': 0.6037},
'children': [
{'value': {'type': 'PROBABILITY', 'distribution': [0.314, 0.686], 'num_examples': '1309,68.60%'},
'condition': {'type': 'NUMERICAL_IS_HIGHER_THAN','attribute': '特征5','threshold': -0.2251}
]
....
}
-
第二部分:利用d3.js框架编写了plotter.js文件来绘制可视化结果。对应代码如下: ![图片[16]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](//rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/d1da634c1120240519200550.png)
![图片[16]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/d1da634c1120240519200550.png)
照猫画虎仿照绘制指标拆解树
修改plotter.js文件中display_conditiong函数如下:![图片[17]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/b50f78c78020240519200551.png)
待展示的数据
json_tree ={'value': {'type': 'PROBABILITY', 'distribution': [1, 0], 'num_examples': '3000,100%'},
'condition': {'type': 'NUMERICAL_IS_HIGHER_THAN', 'attribute': '总销售量'},
'children': [
{'value':{'type': 'PROBABILITY', 'distribution': [0.70, 0.30], 'num_examples': '2100,70%'},
'condition': {'type': 'NUMERICAL_IS_HIGHER_THAN','attribute': '产品A','threshold': -0.2251},
'children': [{'value': {'type': 'PROBABILITY',
'distribution': [1,0],
'num_examples': '城市A:2100,100%'}}]
},
{'value': {'type': 'PROBABILITY','distribution': [0.20, 0.80],'num_examples': '600,20%'},
'condition': {'type': 'NUMERICAL_IS_HIGHER_THAN','attribute': '产品B','threshold': 1.3376},
'children': [{'value': {'type': 'PROBABILITY',
'distribution': [0.60, 0.40],
'num_examples': '城市A:360,60%'}},
{'value': {'type': 'PROBABILITY',
'distribution': [0.40, 0.60],
'num_examples': '城市B:240,40%'}}]
},
{'value': {'type': 'PROBABILITY','distribution': [0.10, 0.90],'num_examples': '300,10%'},
'condition': {'type': 'NUMERICAL_IS_HIGHER_THAN','attribute': '产品C', 'threshold': -1.0981},
'children': [{'value': {'type': 'PROBABILITY',
'distribution': [0.90, 0.10],
'num_examples': '城市A:270,90%'}},
{'value': {'type': 'PROBABILITY',
'distribution': [0.1815, 0.8185],
'num_examples': '城市B:30,10%'}}]}
]
}
最终输出结果
![图片[18]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/e732c3ccaf20240519200553.png)
绘制精美展示山脊图和多维直方图
joyplot库(其官方github: https://github.com/leotac/joypy)是一个专为Python用户设计的数据可视化工具,主要用于绘制一种名为“峰峦图”(Ridgeline Plots)或简称“Joyplot”的特殊类型的图表。这种图表类型以其独特的美学和信息传达能力而受到青睐,它通过叠加多个核密度估计曲线来展示多个变量或多个类别数据的分布情况。其他用法可以访问其github仓库。下面是案例展示
展示多维山脊图
下面是利用joyplot库来绘制山脊图,其可以展示3维的数据,并较直观的进行两两对比。
# !pip install joypy==0.2.6
import joypy
import pandas as pd
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
from matplotlib import cm
from sklearn.datasets import load_iris
iris, y = load_iris(as_frame=True, return_X_y=True)
iris.columns = ["SepalLength","SepalWidth","PetalLength","PetalWidth"]
iris["Name"] = y.replace([0,1,2], ['setosa', 'versicolor', 'virginica'])
fig, axes = joypy.joyplot(iris,colormap= plt.cm.cool)
plt.cm.cool
![图片[19]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/5b5c81f72020240519200555.png)
展示多维直方图
%matplotlib inline
fig, axes = joypy.joyplot(iris, by="Name", column="SepalWidth",
hist=True, bins=20, overlap=0,
grid=True, legend=False)
效果展示:![图片[20]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/f2f88b026820240519200556.png)
动态图表: 利用Pynimate轻松绘制绘制
Pynimate是一个专为Python设计的第三方数据可视化库(其官方github:https://github.com/julkaar9/pynimate),它主要用于创建动态图表和动画,特别适用于显示随时间变化的数据序列,例如动态柱状图、排序图等。
# !pip install pynimate==1.3.0
import pandas as pd
from matplotlib import pyplot as plt
import pynimate as nim
import mpl_font.noto
import numpy as np
%matplotlib inline
df = pd.DataFrame(
{
"time": ["1960-01-01", "1961-01-01", "1962-01-01"],
"巴西": [1, 3, 5],
"日本": [2, 3, 7],
"韩国": [4, 2, 9],
"法国": [5, 3, 10],
"印度": [1, 4, 14],
}
).set_index("time")
my_fig = nim.Canvas(nrows=1, ncols=2, figsize=(12,7))
#配置柱状图
barh = nim.Barhplot.from_df(data=df.copy(), time_format="%Y-%m-%d"
, ip_freq="2d"
,annot_bars=True
,rounded_edges=True
,xticks=True
,yticks=True
,grid=False
)
barh.set_title("各国的变化趋势")
barh.set_bar_annots(color="#547DB1", size=13)
barh.set_bar_border_props(edge_color="#547DB1",radius=0.3, pad=0.4, mutation_aspect=0.5)
barh.set_time(x=0.92
,y=0.2
,callback=lambda i, datafier: datafier.data.index[i].strftime("%Y-%m")
,size=24)
barh.set_text(
"sum",
callback=lambda i, df: f"总和:{np.round(df.data.iloc[i].sum(),2)}",
size=20,
x=0.72,
y=0.13,
color="#547DB1",
)
bar = nim.Barhplot.from_df(data=df.copy(), time_format="%Y-%m-%d"
, ip_freq="2d"
,palettes=['cool'] #配置颜色
,annot_bars=True #显示柱状图标签
,rounded_edges=True #显示柱状图是否呈现圆形
,xticks=True #显示x轴刻度
,yticks=True #显示y轴刻度
,grid=False #是否显示网格
)
bar.set_title("各国的变化趋势")
bar.set_bar_annots(color="#547DB1", size=13)
bar.set_bar_border_props(edge_color="#547DB1",radius=0.3, pad=0.4, mutation_aspect=0.5)
bar.set_time(x=0.92,y=0.2,callback=lambda i, datafier: datafier.data.index[i].strftime("%Y-%m"),size=24)
bar.set_text(
"sum",
callback=lambda i, df: f"总和:{np.round(df.data.iloc[i].sum(),2)}",
size=20,
x=0.72,
y=0.13,
color="#547DB1",
)
# my_fig.ax 获得matplotlib的ax
my_fig.ax[0][0].spines["top"].set_visible(False)
my_fig.ax[0][0].spines["right"].set_visible(False)
my_fig.ax[0][0].spines["bottom"].set_visible(False)
my_fig.ax[0][0].spines["left"].set_visible(False)
my_fig.ax[0][1].spines["top"].set_visible(False)
my_fig.ax[0][1].spines["right"].set_visible(False)
my_fig.ax[0][1].spines["bottom"].set_visible(False)
my_fig.ax[0][1].spines["left"].set_visible(False)
my_fig.add_plot(barh,index=(0,0))
my_fig.add_plot(bar,index=(0,1))
my_fig.animate()
my_fig.save(filename="demo", fps=24, extension="gif")
plt.show()
效果展示:![图片[21]|数据可视化-万字长文: python可视化之17种精美图表实战指南|融云数字服务社区丨榕媒圈BrandCircle](http://rongmeiquan.oss-cn-shenzhen.aliyuncs.com/my-bucket/2024/05/fabc69004820240519200558.gif)
matplotlib实战基础教程
参考文档
-
https://github.com/gyli/PyWaffle -
https://github.com/pog87/PtitPrince -
https://github.com/znstrider/plottable -
https://plottable.readthedocs.io/en/latest/notebooks/plots.html -
https://github.com/jnothman/UpSetPlot -
https://github.com/konstantint/matplotlib-venn -
https://posit-dev.github.io/great-tables/get-started/basic-header.html -
https://github.com/suyin1203/dtreeplot -
https://github.com/dmikushin/pybaobab -
https://github.com/parrt/dtreeviz -
https://github.com/leotac/joypy -
https://github.com/julkaar9/pynimate
z先生说
今天给大家分享数据分析中,高达17种高级图表可视化技术,并附带详细的python案例,干货满满。大家在实际的业务数据,选择合适的图表进行展示~
如果本文对你有帮助,还请你点赞在看转发。你的支持就是我创作的最大动力,关注下面公众号不迷路~
👉往期文章精选












暂无评论内容